
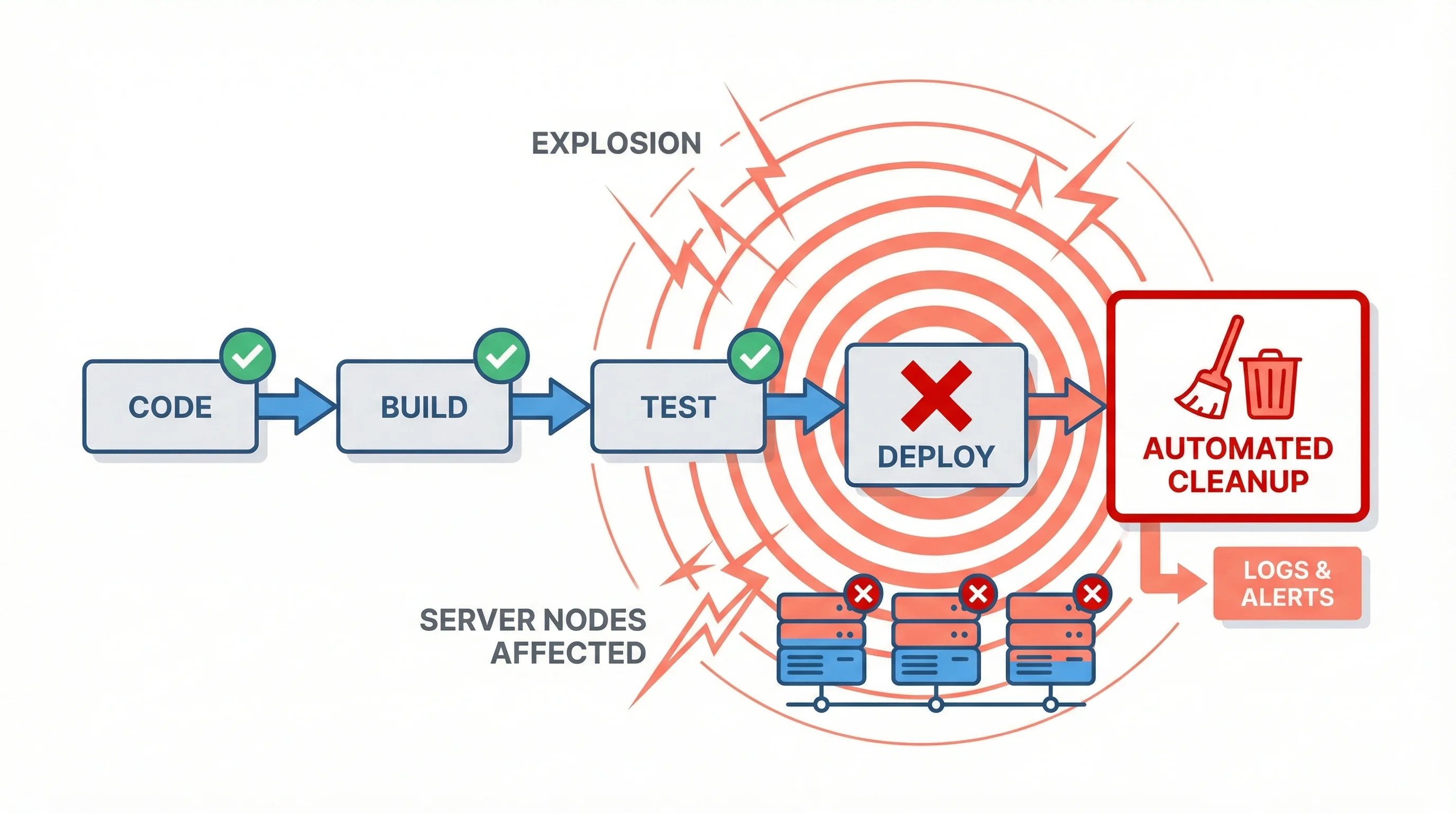
On 20 February 2026, a routine cleanup script at Cloudflare went wrong in the worst possible way. An empty string in an API filter caused the system to select every BYOIP (Bring Your Own IP) prefix in the account, not just the pending ones marked for removal. Within seconds, 1,100 of the company's 4,306 customer IP prefixes were withdrawn from the global routing table. BGP routes vanished. Traffic stopped. Services including Uber Eats, Bet365, Wikipedia, Workday, Minecraft, and Microsoft Outlook went dark.
The outage lasted 6 hours and 7 minutes. For a company that processes requests for roughly 21% of all websites on the internet, that's not a blip. It's a lesson.
And it's the third time in a single month that a major cloud provider has had automation delete production infrastructure.
What Actually Happened at Cloudflare
Cloudflare's BYOIP service lets customers announce their own IP address ranges through Cloudflare's network. Businesses that own IP space use this to get Cloudflare's DDoS protection and CDN performance without changing their addresses. (Cloudflare's own 2026 threat report shows DDoS attacks doubled to 47.1 million last year, which explains why that protection matters.)
The cleanup script was supposed to remove only prefixes in a "pending deletion" state. But the API query used to filter those prefixes contained an empty string, which matched everything. According to Cloudflare's post-mortem, the script ran with production credentials that had full write access to the BYOIP system. No dry-run. No confirmation step. No scope limit on how many prefixes could be deleted in a single operation.
The result: 25% of all BYOIP prefixes were withdrawn from BGP in one go. Customer traffic that relied on those IP ranges had nowhere to go.
Cloudflare's engineering team acknowledged the failure directly. "We let you down today," the post-mortem reads, before detailing the root cause and the remediations now in place.
Three Providers, Three Automation Failures, One Month
Cloudflare's outage didn't happen in isolation. February 2026 has been a brutal month for cloud reliability, and the pattern is impossible to ignore.
Azure, 2-3 February. Microsoft's health monitoring system detected an issue in its backend and triggered an automated remediation. That remediation made the problem worse. The health checker detected the worsened state and triggered more remediation. This feedback loop cascaded across Azure regions for over 24 hours. Microsoft 365 services, including Teams and Outlook, were disrupted for businesses worldwide.
AWS, 16 February. Amazon's AI coding tool Kiro, running with overly broad permissions, autonomously deleted and rebuilt a live AWS environment. The incident, first reported by the Financial Times, took down AWS Cost Explorer in China for 13 hours. Amazon disputes the "AI autonomy" framing, but the outcome is the same: automated tooling destroyed production infrastructure because permissions weren't scoped correctly.
Cloudflare, 20 February. An empty string in an API query caused a cleanup script to delete 1,100 BYOIP prefixes, knocking out traffic for 25% of BYOIP customers for over six hours.
Three separate providers. Three separate root causes. But the underlying failure is identical in each case: an automated process with too much access, no safety check, and no limit on how much damage it could do in a single operation.

The Root Cause Behind the Root Cause
Every post-mortem focuses on the technical trigger. The empty string. The feedback loop. The misconfigured permissions. But the real problem sits one level deeper: automation runbooks are being deployed without blast-radius controls.
Research from CyberSecurity News cites industry data suggesting roughly a third of cloud outages now involve some form of automated remediation or maintenance script going wrong. That number has been climbing as providers push more operational tasks from human-led to fully automated.
The logic makes sense: automation reduces human error and speeds up routine tasks. But when the automation itself fails, it fails at machine speed. A human technician withdrawing BGP routes might do ten, notice something odd, and stop. A script with production credentials does 1,100 before anyone can react.
"When a digital service depends entirely on a single cloud platform, that single point of failure extends to everything built on top of it. The February incidents are a strong signal that businesses need to think harder about redundancy."
Mayur Upadhyaya, CEO of APIContext
That's the quiet part said out loud. The cloud was supposed to eliminate single points of failure. Instead, concentration has created new ones. Cloudflare handles traffic for over 41 million websites. When its automation misfires, the blast radius isn't one company or one region. It's a chunk of the internet.
What This Means for Your Business
If you run a website, you almost certainly depend on at least one of these providers, even if you don't know it. Your WordPress hosting company uses a CDN. Your DNS provider routes through a major network. Your email transits through infrastructure that sits on top of the same platforms that failed in February.
The question isn't whether your stack has exposure to a hyperscaler outage. It does. The question is what happens when that exposure gets triggered.

Here's what's worth checking:
DNS resilience. If your DNS provider uses a single upstream network and that network drops routes, your domain stops resolving. Use the 365i DNS Lookup tool to check your current nameserver configuration and email authentication records. Consider whether your DNS setup has a fallback path.
CDN dependency. A CDN that sits in front of your site is also a single point of failure. If the CDN goes down, your origin server should still be reachable. Ask your hosting provider whether your site falls back to origin or goes offline entirely. Our CDN is designed to fail open, so sites remain accessible even if edge nodes are disrupted.
Monitoring and alerts. The Cloudflare outage lasted six hours. How quickly would you know if your site went down? Services like UptimeRobot or Pingdom can alert you in minutes. The earlier you know, the faster you can switch DNS or take other recovery steps. Use our HTTP Header Inspector to verify your site's response headers and redirect chains are healthy right now.
Multi-provider awareness. You don't need to run your own data centre. But you should know where your single points of failure are. Which providers does your hosting company depend on? What's their failover strategy? At 365i, we use managed cloud infrastructure across multiple providers (365i, AWS, Google Cloud) specifically because concentration risk is real.
What Cloudflare Is Doing About It
Credit where it's due: Cloudflare's post-mortem is thorough. They've committed to several remediations including rate-limiting deletion operations, adding mandatory dry-run steps for bulk changes, reducing the scope of service account permissions, and implementing a "two-person rule" for changes affecting large numbers of prefixes.
These are the right fixes. They're also the fixes that should have been in place before the incident. Every one of them is a standard practice in production server security: principle of least privilege, blast-radius controls, confirmation steps for destructive operations.
Azure and AWS have issued their own remediations after their February incidents. The pattern across all three is the same: add the guardrails that were missing. The uncomfortable truth is that these guardrails were well understood long before February 2026. They just weren't applied to the automation layer.
Five Questions to Ask Your Hosting Provider
You don't need to understand BGP routing tables or BYOIP prefix management. But you should be able to get straight answers to these questions:
- What's your CDN and DNS failover? If your CDN provider has an outage, does my site go offline or fall back to origin?
- Where are my single points of failure? Which upstream providers does your infrastructure depend on?
- How do you handle provider outages? Is there a documented incident response process?
- What monitoring do you run? How quickly would you detect a BGP withdrawal or DNS resolution failure?
- Do you use multiple data centre locations? Geographic redundancy protects against regional failures. 365i's platform runs across UK, US, and Asia data centres for this reason.
If your provider can't answer these clearly, that itself is an answer.
A Pattern That's Getting Worse
The web is more concentrated than it's ever been. A handful of companies, Cloudflare, AWS, Azure, Google Cloud, carry the majority of internet traffic. That concentration delivers real benefits: better performance, easier management, lower costs. It also creates systemic risk that didn't exist when the web was more distributed.
February 2026 is a preview of what happens when automation at that scale goes wrong. Not once, but three times in four weeks. The businesses that came through it best were the ones that already had redundancy built in: fallback DNS, multi-CDN setups, hosting platforms designed for resilience rather than minimum cost.
If you're reviewing your hosting setup after reading this, that's the right response. Check your SSL configuration, verify your DNS records, and make sure you know what happens when one link in your chain breaks. The next outage won't wait for you to get ready.
Frequently Asked Questions
What caused the Cloudflare outage on 20 February 2026?
A cleanup script designed to remove unused BYOIP prefixes contained an empty string in its API filter. Instead of selecting only prefixes marked for deletion, it matched all 4,306 prefixes and deleted 1,100 of them. This withdrew the associated BGP routes, causing traffic to those IP ranges to stop globally.
How long did the Cloudflare outage last?
6 hours and 7 minutes from initial impact to full recovery. Cloudflare's engineering team had to re-announce the deleted BGP prefixes and wait for global routing tables to propagate the corrected information.
Which websites and services were affected?
Directly affected services included Uber Eats, Bet365, Wikipedia, Workday, Minecraft, and Microsoft Outlook, among others. Any business using Cloudflare's BYOIP service with a prefix in the deleted batch lost connectivity for the duration of the outage. Sites using Cloudflare's standard CDN (without BYOIP) were not affected.
What is BYOIP and why does it matter?
BYOIP (Bring Your Own IP) lets businesses announce their own IP address blocks through Cloudflare's network. Large organisations use it to keep their existing IP addresses while gaining Cloudflare's DDoS protection and CDN performance. When those prefixes were withdrawn from BGP, traffic for those IPs had no route to follow.
Were there other major cloud outages in February 2026?
Yes. Azure had a 24-hour outage on 2-3 February caused by an automated health checker entering a remediation feedback loop. AWS had a 13-hour outage on 16 February when Amazon's AI coding tool Kiro deleted and rebuilt a live environment with overly broad permissions. All three incidents involved automated processes failing without adequate safety controls.
Was my website affected by the Cloudflare outage?
If your site uses Cloudflare's standard CDN (the free or paid plans most small businesses use), you were not directly affected. The outage specifically hit BYOIP customers, which are typically larger organisations that own their own IP address space. However, if any service your site depends on (email, payment processing, third-party APIs) used an affected IP range, you may have experienced indirect disruption.
How can I protect my business from cloud provider outages?
Focus on removing single points of failure. Use DNS providers that support failover. Check whether your CDN fails open (falling back to your origin server) or fails closed (taking your site down entirely). Set up uptime monitoring so you're alerted within minutes. And ask your hosting provider which upstream providers they depend on and what their failover strategy looks like.
What is Cloudflare doing to prevent this from happening again?
Cloudflare's post-mortem commits to rate-limiting deletion operations, mandatory dry-run steps for bulk changes, reduced permissions for service accounts, and a two-person approval rule for changes affecting large numbers of prefixes. These are standard production safety practices that weren't applied to the automation that caused the incident.
Check your site's infrastructure health
Use our free DNS Lookup, HTTP Header Inspector, and SSL Scanner to verify your site's configuration. No sign-up needed.
View Free ToolsSources
Published: · Last reviewed: · Written by: Mark McNeece, Founder & Managing Director, 365i
Editorially reviewed by: Mark McNeece on · Our editorial standards



